מחקר מקיף בחן את השיח הפוליטי בדרשות בבתי כנסת בארצות הברית בשנים האחרונות.
מאת: ד"ר גילה אמאטי, שלומי ברזניק
מאת: ד"ר גילה אמאטי, שלומי ברזניק

איסוף הנתונים
מחקר זה ניתח קורפוס של 4,302 דרשות שניתנו בארצות הברית בבתי כנסת רפורמיים, קונסרבטיביים ואורתודוקסיים-מודרניים, 2,556 מהן בין אוקטובר 2021 לאוקטובר 2024. תפוצת הדרשות בשלושת הזרמים משקפת הן את היכולות הטכנולוגיות ואת הנגישוּת הדיגיטלית והן את החלק היחסי של יהודים המשתייכים לכל זרם. מאגר הנתונים כולל 1,276 דרשות מבתי כנסת רפורמיים, 878 מבתי כנסת קונסרבטיביים ו־412 מבתי כנסת אורתודוקסיים־מודרניים; רוב הדרשות האורתודוקסיות־מודרניות הן מן השנתיים האחרונות.
התרשימים המוצגים כאן מסרטטים את הפיזור הגאוגרפי של הדרשות ומבהירים את המגמות הכלליות בתיעוד הדרשות לאורך זמן. התרשים הראשון מציג את התפלגות הדרשות שניתנו בשנים 2024-2006 בחלוקה לארבעה אזורים גאוגרפיים עיקריים: ניו יורק, החוף המערבי, החוף המזרחי (מלבד ניו יורק) ואזור המערב התיכון ודרום־מזרח ארצות הברית (Midwest/Southeast).
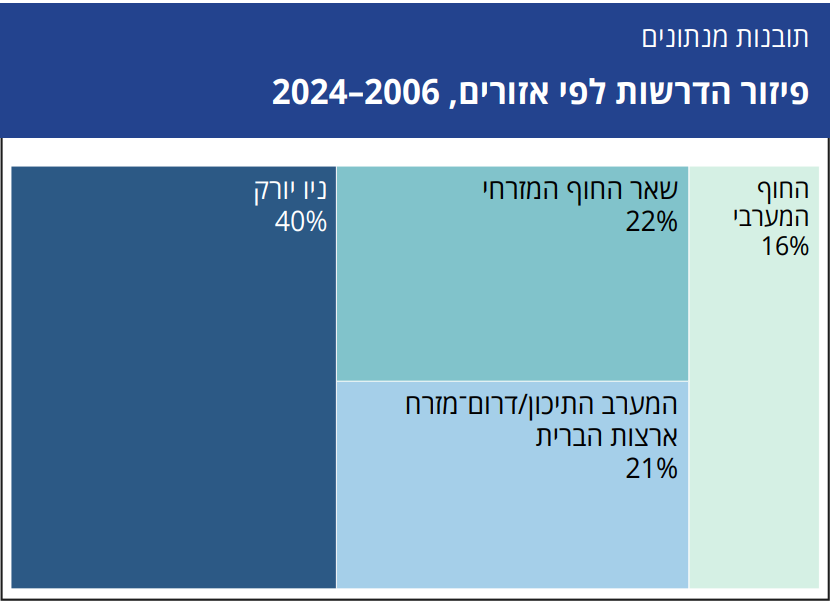
מספר הדרשות הגדול ביותר, כלומר 40% מכלל הדרשות המתועדות, הן מניו יורק. אחריה בדירוג נמצאים החוף המזרחי (22%) והמערב התיכון/דרום־מזרח ארצות הברית (21%). 16% מהדרשות נמסרו בחוף המערבי. החלק היחסי הגבוה של ניו יורק תואם את גודל האוכלוסייה היהודית שם, על שפע הקהילות, בתי הכנסת והמוסדות היהודיים הממוקמים באזור. התרשים השני מתמקד בתקופה שבין אוקטובר 2021 לאוקטובר 2024 וחושף תמונת פיזור אחרת מעט.
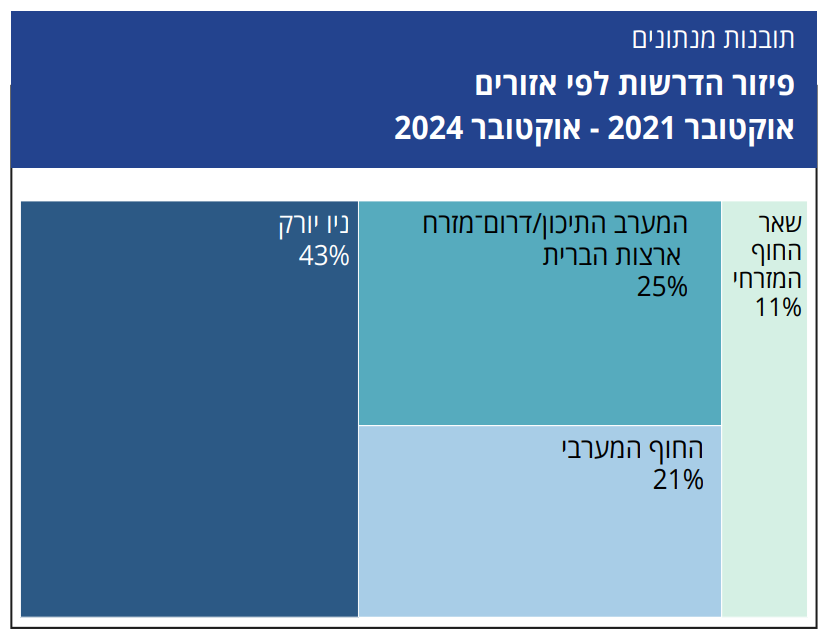
בפרק הזמן הזה, החלק היחסי של ניו יורק במספר הדרשות עלה ל־43%, ואילו החלק של החוף המזרחי ירד ל־11%. 25% מן הדרשות ניתנו במערב התיכון/דרום־מזרח, ו־21% בחוף המערבי. תמונת מצב זו מספקת מבט עדכני יותר על הפיזור הגאוגרפי של הדרשות בתוך מסגרת הזמן המוגדרת, שהיא המקור לרוב הניתוח שלהלן.
התרשים השלישי מתאר את מספר הדרשות שהועלו לרשתות בכל שנה בשנים 2024-2006.
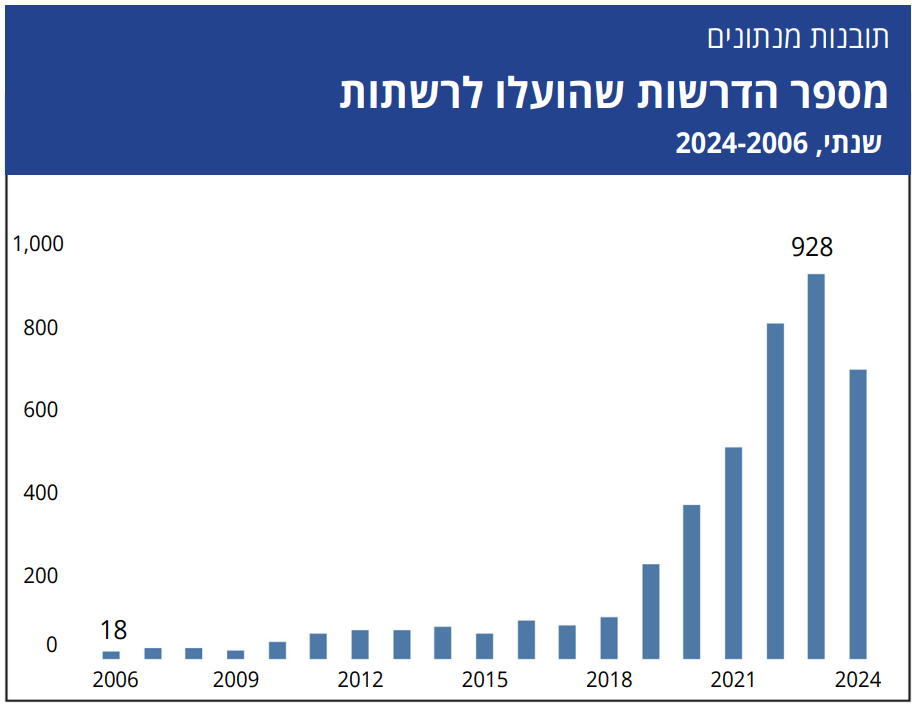
הנתונים מראים גידול הדרגתי בשנים הראשונות, עם מספרי העלאות נמוכים יחסית עד שנת 2016 בערך. מנקודה זו ואילך גדל מאוד מספר הדרשות שמועלות בכל שנה לרשתות, שהגיע לשיא ב־2023. הסיבה לירידה ב־2024 היא שהדרשות שנכנסו למאגר הנתונים הגיעו רק עד אוקטובר 2024, כלומר חודשיים פחות בהשוואה לשנים הקודמות. המגמה הכללית מצביעה על התרחבות בתיעוד הדרשות במרוצת הזמן.
הדרשות מן הקהילות הרפורמיות והקונסרבטיביות נאספו בעיקר בעזרת ממשק יישומים (API) המבוסס על Python, שתמלל אותן ישירות מיוטיוב. כדי לבצע את ההליך הזה היה צורך לחלץ את הדרשות מתוך רשימת האזנה ייעודית שנוצרה במיוחד לתכלית זו. הממשק אִפשר שליפה אוטומטית של "נתוני נתונים" מרכזיים (מטא־דאטה), ובכלל זה כותרת הדרשה, תמליל מלא וחותמת זמן. שיטה זו הבטיחה איסוף נתונים שיטתי ויעיל שאִפשר ניתוח מקיף של השיח הפוליטי בדרשות בזרמים שנחקרו.
איסוף הנתונים מן הקהילות האורתודוקסיות־מודרניות חייב גישה ישירה יותר, בשל הנגישות המוגבלת יחסית של תוכן הדרשות. הדרשות התקבלו לאחר פנייה ישירה לרבנים ולראשי הקהילות והוגשו בפורמטים שונים, כולל קובצי word ו־PDF. כדי להבטיח אחידות הומרו תחילה כל הדרשות מזרם זה לפורמט PDF ואחר כך עובדו בעזרת ספריות Python כדי לחלץ את הטקסט ולהבנות אותן בתוך תיקיות CSV סטנדרטיות, המכילות את כותרת הדרשה, את הטקסט המלא, את שם הרב ואת התאריך. במקרים שבהם חסר התאריך הלועזי המדויק, או שצוין רק התאריך העברי, נעשה שימוש ב־ChatGPT-4o כדי לקבוע תאריך משוער לכל הפחות במטרה להבטיח עקביות בזמנים לכל רוחב מאגר הנתונים. כך התאפשר לנו להשוות בין דרשות מתקופות שונות.
כדי לשמור על העקביות בין שלושת הזרמים הכנסנו את כל הדרשות שנאספו לפורמט CSV אחיד. צעד זה סייע לנו לנהל את הנתונים ביעילות והבטיח את אפשרות ההשוואה בין הדרשות מן המסורות היהודיות השונות.
ניתוח הנתונים
מסגרת עבודה מתודולוגית: ניתוח שיח חישובי ואופטימיזציה בעזרת בינה מלאכותית
בעבודתנו על מחקר זה השתמשנו במגוון שיטות חישוביות ולשוניות מתקדמות כדי להגיע למרב הדיוק, הלכידות והעומק בניתוח הנתונים. לנוכח מורכבות השיח הדרשני ונקודות המפגש שלו עם תמות פוליטיות היה חיוני לבנות את המפגש בין בינה מלאכותית לטקסט באופן שימקסם את יכולת הפרשנות בד בבד עם שימור הדקויות של הרכיבים הרטוריים בדרשות. לשם כך השתמשנו בשילוב של שיטות הנדסת פרומפטים, מהלכי עבודה אנליטיים מובְנים וטכנולוגיות היסק (reasoning) מותאמות בינה מלאכותית שאפשרו להעמיק בחומרים.
הכוונת המודל באמצעות דוגמאות (Few-Shot Learning)
כדי לדייק עוד יותר את הפרשנות של המודל השתמשנו בגישת Few-shot learning.27 במקום להציג לבינה המלאכותית שאלות מחוץ להקשר שיבצנו דוגמאות של מבני תגובה צפויים בתוך הפרומפטים. צעד זה שיפר את יכולות המודל לניתוח קוהרנטי ומותאם יותר להקשר.
טכניקת CoT (Chain of Thought): קידום בפרשנות עוקבת (sequential interpretive logic)
מתוך ההבנה שהמבנה הרטורי של הדרשות הוא רב־שכבתי שילבנו במחקר את טכניקת CoT, המחייבת את הבינה המלאכותית לפרט את נימוקיה צעד אחר צעד לפני הפקת התשובה הסופית.28 על ידי הבניית התשובות באופן הדומה לפרשנות עוקבת אנושית הבטיחה גישתנו זו שהניתוח של הבינה המלאכותית יחקה את סוג ההנמקה המובנית המתקיימת בניתוח שיח אנושי.
פילוח מטלות פרשנות לטובת יתר דיוק (Decomposed Prompting)
במקום הגישה הקונבנציונלית של שאלה יחידה בכל פעם יישמנו טכניקת פירוק שמאפשרת ניתוח מדויק ומובנה יותר של השיח הדרשני. במקום להטיל על הבינה המלאכותית לזהות ולפרש תוכן פוליטי בעת ובעונה אחת חילקנו את תהליך הניתוח לשלבים מובחנים.
ניתוח פרטני: שמירה על השלמוּת ההקשרית
היות שדרשות מתקיימות כאירועים רטוריים נפרדים, כל טקסט נותח פרטנית ולא כחלק מקבוצה גדולה. החלטה מתודית זו התקבלה מתוך ההכרה שהקול המובע בדרשה הוא תְּלוי הֶקשר: התמות שהוא מביא, התקבלותו בקרב הקהל והפונקציה הרטורית שלו משתנים מאוד בהתאם לזרם, למיקום ולאווירה החברתית־פוליטית. ההתייחסות לכל דרשה כאל יחידת ניתוח אוטונומית הבטיחה את שמירת השלמות ההקשרית ומנעה רידוד של המשמעות על ידי עיבוד מרובה פרטים.
פלט חישובי מובנה: תִּקְנון השיח לצורך ניתוח שיטתי
כדי לאפשר גישה מתודית קפדנית לתובנות המתקבלות באמצעות הבינה המלאכותית עשינו פירמוט לתשובות במבנה JSON. באמצעות פעולה זו הבטחנו סטנדרטיזציה בכל שלבי העיבוד החישובי. מבנה זה לא רק סייע להשיג יעילות בפירוק ובסיווג, אלא גם אִפשר להצליב מידע בין ניתוחי הבינה המלאכותית לבין הפרשנות האנושית.
שלבי הניתוח
התהליך האנליטי חולק לכמה שלבים מובנים כדי לוודא בדיקה מקיפה ושיטתית של השיח הדרשני. המתודולוגיה כללה שילוב של סיווג באמצעות בינה מלאכותית; ניתוח הלך הרוח בדרשות; והערכת המבנה שלהן לצורך הפקת תובנות לגבי התוכן הפוליטי, הביקורת על ישראל, מסרים חיוביים ומגמות תמטיות.
ניתוח כללי של הדרשות
השלב הראשוני של הניתוח כלל בדיקה נרחבת של מאגר הנתונים המלא כדי לייצר מערכת סיווג בסיסית ולהבטיח עקביות מתודולוגית. הצעד הראשון היה לאמת שכל פיסת טקסט שנותחה היא אכן דרשה, שלא כמו תצורות שיח אחרות. השלב הבא בתהליך היה לזהות אם דרשה מסוימת מכילה תוכן פוליטי. לשם כך מיַנּו את הדרשות לקטגוריות "פוליטי" ו"לא־פוליטי". לצורך חידוד נוסף קבענו אילו מן הדרשות הפוליטיות מתמקדות בפוליטיקה של ישראל.
נוסף על הזיהוי של תמות פוליטיות, כאשר הייתה התייחסות לישראל הכנסנו עוד דרגת מיון כדי להעריך את הלך הרוח הכללי בדרשות. גישה זו אפשרה לנו להבין את דקויות הניסוח של התמות הפוליטיות, בייחוד אלה שנוגעות לישראל, וכיצד הן מוסגרו בתוך ההקשר בזרמים השונים – כל זה כדי לאפשר ניתוח השוואתי של נימת הדברים והדגשים בכל הדרשות שנחקרו.
מיון הדרשות המכילות ביקורת על ישראל
לצורך זיהוי שיטתי של הביקורות על ישראל בדרשות הגדרנו מראש שורה של תמות ביקורתיות. במקום לשאול באופן כללי אם דרשה מסוימת מכילה ביקורת, הנחינו את CharGPT-4o לנסות לאתר בכל דרשה בנפרד נוכחות של תמות ספציפיות. גישה זו הבטיחה מיון מובנה וממוקד, עם פחות דו־משמעויות ועם דיוק רב יותר. הבינה המלאכותית התבקשה להעריך דרשות שבהן כבר זוהתה מעורבות עם ישראל ולקבוע אם מופיעה בהן תמה ביקורתית אחת או יותר מאלה שהוגדרו מראש.
מתודולוגיה זו הניבה ניתוח גרעיני יותר, ובעזרתו יכולנו להשוות בין הביקורות הנמתחות על ישראל בזרמים השונים ובתקופות שונות. על ידי הבניית המטלה בדרך זו וידאנו שכל נושא ביקורתי יתוקף באופן עצמאי, מה שאפשר חקירה מדוקדקת יותר של השיח הפוליטי בדרשות. מיון זה התבצע רק בדרשות שזוהו לפני כן כבעלות תוכן פוליטי וכמפגינות מעורבות בענייני ישראל.
ניתוח של מבנה הדרשות
כדי לבחון את תפקיד המבנה בשיח הפוליטי בדרשות עשינו פילוח תוכן שבדק איך ומתי הופיעו התכנים הפוליטיים בדרשה. בניתוח הדרשות שסווגו כפוליטיות הקדשנו תשומת לב מיוחדת לפרק הפותח את הדרשה, ובדקנו בעין בוחנת יותר רק את ה־20% הראשונים. בדרך זו התחוור לנו אם התוכן הפוליטי הוצג בתחילת הדרשה או הופיע בשלב מאוחר יותר של הדיון הדתי או הערכי. הטלנו על CharGPT-4o לזהות את הדפוסים המבניים הללו ולהבחין בין הדרשות שנפתחו בנושאים פוליטיים ברורים לבין אלה שנפתחו במוטיבים דתיים. הזנת דוגמאות מובְנות מכל סוג הבטיחה עקביות בסיווג וסייעה לשמור על גישה קפדנית ושיטתית כדי לעמוד על יחסי הגומלין בין השיח הפוליטי לשיח הדתי.
סיווג המסרים החיוביים בדרשות
איתור המסרים החיוביים בדרשות התבצע במאגר הנתונים כולו על מנת לזהות ביטויים של עידוד, אחדות וקריאות לפעולה. הטלנו על CharGPT-4o לזהות מופעים של מסרים חיוביים בכל דרשה ולאחר מכן לספק רשימה מובנית של המסרים הללו על פי הקטגוריות שהוגדרו מראש. הניתוח התמקד במסרים חיוביים כלליים במגוון תמות רחב של עידוד וסולידריות קהילתית.
ניתוח נושאים ספציפיים: החטופים, הפסקת האש והעלייה
כדי לדייק עוד יותר את חקירת השיח הפוליטי בדרשות עשינו ניתוח מעמיק לנושאים ספציפיים בעלי משמעות מיוחדת לתקופה שאחרי מתקפת 7 באוקטובר. נושאים אלה נותחו בעזרת הערכת נפח מבוססת נושא. זו בחנה – על סמך יכולות המידול הנושאי (topic modeling) של CharGPT-4o – באיזו מידה נושאים אלו בולטים בדרשות העוסקות בישראל. גישה זו אפשרה לנו להעריך באיזו תדירות הנושאים הללו מופיעים בדרשות. נושא העלייה לישראל נבדק על ידי ניתוח השכיחות של המילה "Aliyah", בשל ההוראה הלשונית הייחודית שלה. מתודה זו אפשרה למדוד במדויק את נוכחות המילה בזרמים השונים ומתוך כך להבין אם הרבנים מתחברים לרעיון העלייה לישראל.
ליטוש המודל האנליטי
גישה רב־שכבתית זו הבטיחה שהמחקר יעמיק מעֵבר לאיתור מילות מפתח בסיסיות ויכלול את הדקויות התמטיות, את מבנה השיח ואת השינויים בהלך הרוח לאורך זמן. השילוב של מיון תוכן בעזרת בינה מלאכותית לצד פיקוח אנושי מובנה סייע לנו ליצור מסגרת עבודה שיטתית ומוקפדת שאפשרה לנו לבחון לפרטי פרטים את השיח הפוליטי בדרשות הרבנים בזמננו.
טכניקות תיקוף
לצורך תיקוף אמין ומדויק של הממצאים שהושגו באמצעות הבינה המלאכותית השתמשנו בגישת HITL (Human-In-The-Loop). בתהליך תיקוף זה משתתפים מומחיוּת אנושית בצד ניתוח חישובי. המטרה היא למתֵּן דעות מוטות ולהגביר את המהימנות. במקום שנסתמך על הסיווג האוטומטי בלבד מסרנו לקוראים אנושיים מדגם של דרשות שמוינו על ידי בינה מלאכותית והם השוו אותן לפרשנויות אנושיות כדי להבטיח עקביות. בנוסף, בחנּו לעומק את תהליך ההיסק (reasoning) של ChatGPT-4o כדי להבין כיצד הגיע המודל למיון שאליו הגיע. צעד זה היה הכרחי כדי ללטש את הדיוק הפרשני של הבינה המלאכותית וכדי לוודא שקבלת ההחלטות שלה עולה בקנה אחד עם אופיו רב הדקויות של השיח הדרשני.
לצורך הערכת הביצועים של ChatGPT-4o במיון הדרשות השתמשנו במדדים סטנדרטיים של דיוק ושליפת מידע (accuracy, precision, recall). מדדים אלה סיפקו תובנות על החוזקות ושל המגבלות של המודל במטלות ניתוחיות שונות.
מדד ה־accuracy מעריך את התדירות שבה המודל ממיין נכונה את הדרשות הפוליטיות והלא־פוליטיות אגב שילוב מיונים נכונים חיוביים ושליליים כאחד. תוצאה גבוהה מלמדת שהבינה המלאכותית מבחינה ביעילות בין דרשות רלוונטיות ושאינן רלוונטיות. אלא שמדד זה לבדו לא תמיד מספיק, בייחוד במקרים שמאגר הנתונים אינו מאוזן וסיווגים מסוימים שכיחים בו פחות.
כדי לתת מענה למגבלה זו השתמשנו במדד ה־precision – מדד משלים שבודק את מהימנות הזיהוי החיובי במודל. מדד זה מעריך כמה מן הדרשות שזוהו כטעונות פוליטית או כמכילות ביקורת אכן סווגו נכונה. זהו כלי מדידה חשוב במיוחד כשמדובר בזיהוי של סיווג נדיר או ספציפי ביותר, כגון דרשות המכילות ביקורת פוליטית על דמות מסוימת. תוצאת precision גבוהה מבטיחה שכאשר המודל מסווג דרשה כלשהי כפוליטית או כביקורתית, הסבירות שמדובר בזיהוי מדויק ולא בתוצאה חיובית שגויה היא גבוהה יותר.
לדוגמה, במאגר נתונים המכיל גם דרשות פוליטיות וגם לא־פוליטיות מדד ה־accuracy מעריך את מידת הדיוק של ההבחנה בין שתי הקטגוריות באופן כללי. אבל במקרים שרק תת־קבוצה קטנה של דרשות מכילה ביקורת פוליטית, מדד ה־precision מוודא שכאשר המודל מסמן דרשה מסוימת כמכילה ביקורת פוליטית, הזיהוי אכן נכון. על ידי שילוב שני המדדים הללו בהליך התיקוף המחקר מבטיח הערכה מוקפדת ומאוזנת של סיווגי הבינה המלאכותית ומחזק את הביטחון באמינות הניתוח החישובי של השיח הדתי.
עם זאת, הסתמכות בלעדית על precision מציבה אתגרים משלה. מודל שכּוּונן להשגת רמת דיוק זו עלול להפוך לזהיר מדי, והמחיר של מניעת הסיווגים המוטעים עלול להיות החמצת מקרים רלוונטיים. כאן נכנס לתמונה מדד הריקול (recall). מדד זה מעריך את יכולתו של המודל לשלוף את כל המקרים הרלוונטיים מתוך מאגר הנתונים ולכמת את מספר הדרשות הביקורתיות או הטעונות פוליטית שזוהו נכונה מתוך כל הדרשות הקיימות. תוצאת ריקול גבוהה מעידה שהבינה המלאכותית לא רק מדייקת כשהיא מסווגת דרשות כפוליטיות, אלא גם מעריכה את הדרשות באופן מקיף ולא מחמיצה מקרים חשובים של שיח פוליטי.
מדדי התיקוף הללו נועדו למתן את הדעות המוטות, להגביר את מהימנות התובנות המושגות באמצעות בינה מלאכותית ולהבטיח שהניתוח עולה בקנה אחד עם אופייה רב הדקויות של הדרשנות הדתית. על ידי שילוב ניתוח חישובי עם מומחיות אנושית מחקרנו זה שואף לספק בדיקה מקיפה של השיח הפוליטי בדרשות הרבנים בארצות הברית בכל שלושת הזרמים וההקשרים החברתיים־פוליטיים המגוּונים שנבדקו.